
大数据成矿预测系列(一) | 经典模型“证据权重法”的前世今生
前言在大数据成矿预测的古今发展过程中,已经诞生了多种方法,整体上可归纳为三大类:知识驱动型、数据驱动型以及融合驱动型。
本系列文章将首先从数据驱动型方法入手展开介绍,其他类型的方法将会在后续推文中进行讨论,敬请关注微信公众号“码上地球——数学地球科学”以获取最新内容。
本文聚焦于数据驱动型的地学统计与空间分析方法,包括但不限于:
证据权重法(Weights of Evidence)
信息量法(Information Value Method)
多准则决策分析(Multi-Criteria Decision Analysis)
空间点模式分析(Spatial Point Pattern Analysis)
我们将依次介绍每种方法的原理、适用场景与案例,旨在通过回顾历史发展的脉络,帮助读者更好地理解这些方法,从而为未来成矿预测技术的创新与应用提供借鉴。
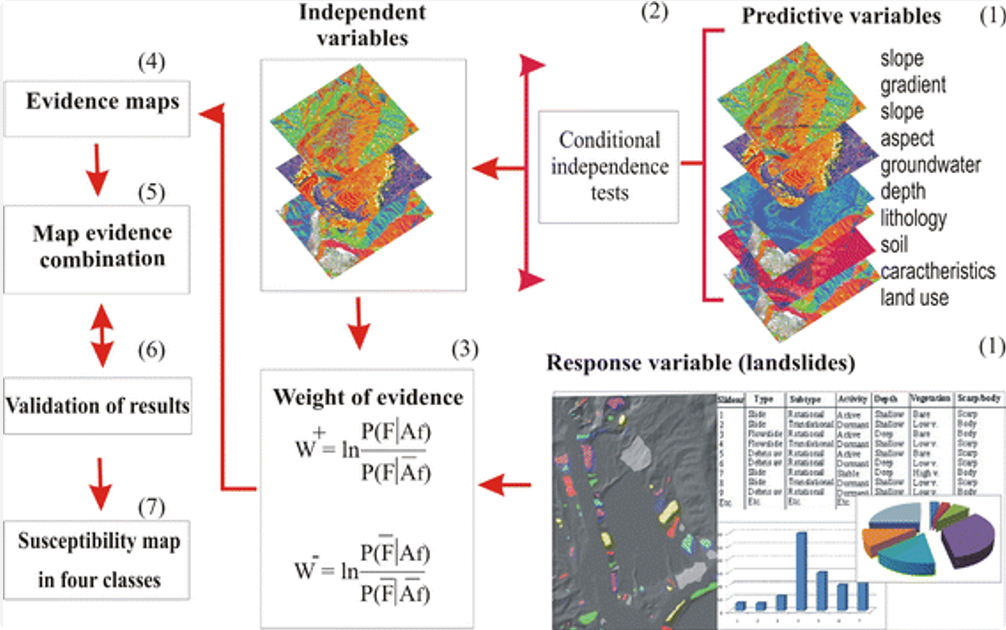
证据权重法如果你的研究方向是地质大数据,那么其中一个重要的应用领域就是矿产远景制图(Mineral Prospectivity Mapping, MPM)。这一方法在文献中也常被称为矿产远景区预测图或矿产远景评价图。无论名称如何,本质上 ...
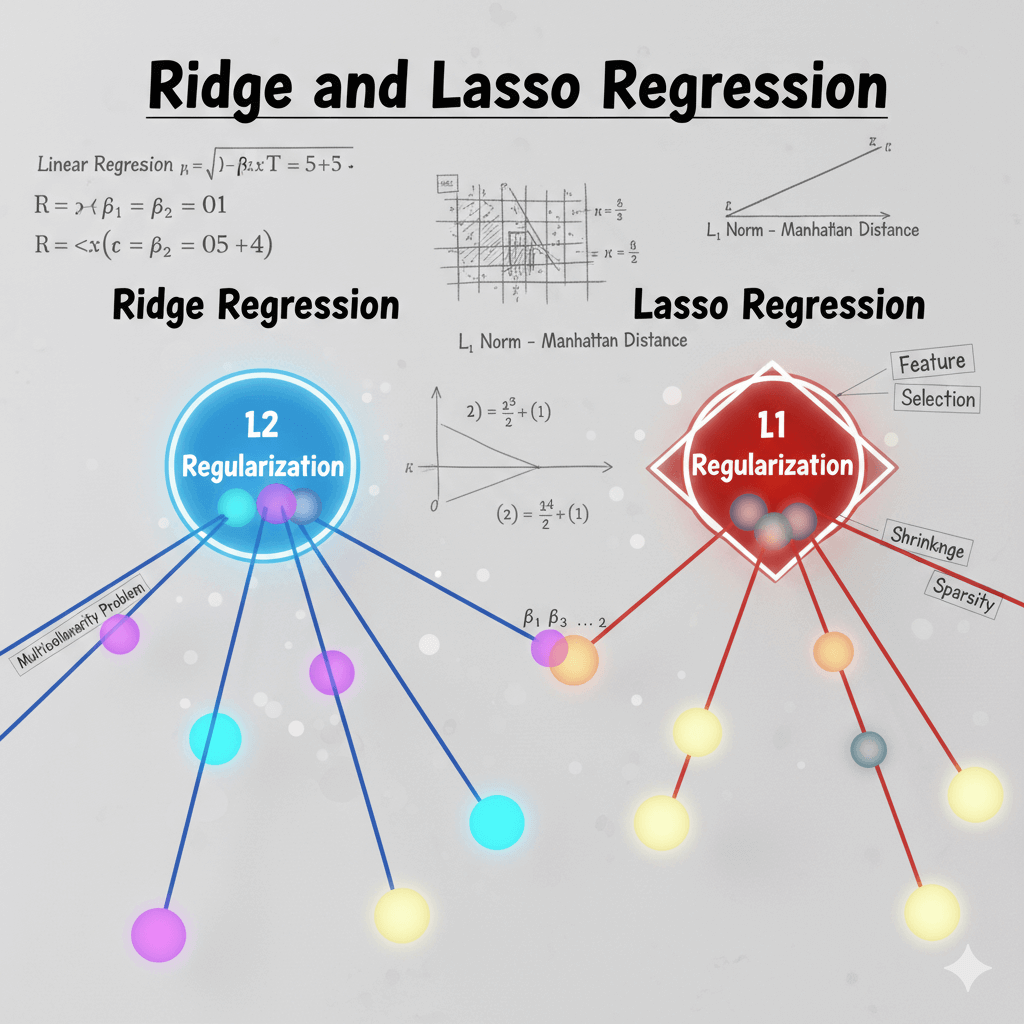
岭回归和 Lasso回归
前言这部分内容本质上是和线性回归相关的,主要是解释什么是岭回归和 Lasso回归,也一定程度和机器学习的一小部分内容相关(概念上)。在阅读这篇文章之前,请确保你对线性回归和多重共线性有一定的了解基础。
请注意,本文并不涉及岭回归的代码实现和数学推导
岭回归什么是岭回归 岭回归(Ridge Regression),是一种专门用于处理多重共线性(特征之间高度相关)问题的线性回归改进算法,显然它是一个回归模型。在多重共线性的情况下,数据矩阵可能不是满秩的,这意味着矩阵不可逆,因此不能直接使用普通最小二乘法(Ordinary Least Squares,OLS)来估计模型参数。岭回归通过在损失函数中添加一个正则化项(惩罚项)来解决这个问题。
岭回归也称为Tikhonov正则化(Tikhonov Regularization),这是因为一位名叫安德烈·吉洪诺夫 (Andrey Tikhonov) 的苏联数学家为“不适定问题” (ill-posed problems)”提出了通用且强大的解决方法。他的方法核心就是:在原始的目标函数上,增加一个惩罚项(也就是正则化项),来约束解的平滑性,从 ...

卷积神经网络设计指南:从理论到实践的经验总结
前言这部分涉及的内容需要有一定的卷积神经网络基础支持,包括但是不限于了解:卷积核,池化,归一化等基础概念,当然还有一些内容我会及时补充说明。
本文主要讲述经验性质的如何设计卷积神经网络?,这个问题一定对于初次接触卷积神经网络的学者们有不少的困惑。
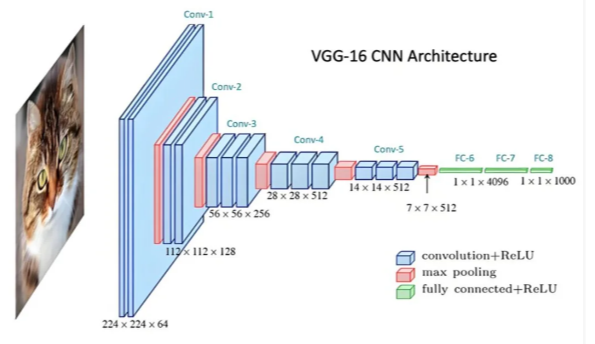
卷积神经网络的结构一个用于图像分类的卷积神经网络 (CNN),其结构通常包含两大核心部分。
前半部分是**特征提取器 (Feature Extractor)**。它主要由一系列卷积层和池化层堆叠而成。卷积层负责识别图像中的局部模式(如边缘、纹理),而池化层则对特征进行降采样,以减少计算量并增强特征的平移不变性。在更复杂的网络中,通常还会引入批量归一化 (Batch Normalization)、通道混洗 (Channel Shuffle) 等技术来优化训练过程和提升性能。
后半部分是**分类器 (Classifier)**。它通常由一个或多个全连接层构成,负责接收并整合前半部分提取出的高级抽象特征,并最终输出每个类别的预测概率。
因此,用于分类的 CNN 本质上可以视为一个特征提取器与分类器的组合体。从这个角度理解,我们也可以灵活地选用其 ...
因子分析基础指南:原理、步骤与地球化学应用解析
前言在看深度学习成矿预测以及地球化学数据分析的文献的时候很多引言部分的内容会提到一些老的技术,正所谓:知其然知其所以然。所以我把关于一些老技术的基础铺垫的内容作为:研究生基础指南部分进行记录。
这部分讲述的是因子分析(Factor Analysis),这部分将会说明如下几点内容:
什么是因子分析?
因子分析的原理
因子分析和主成分分析(PCA)的区别
注:请确保你已经先掌握了主成分分析(PCA)方法
什么是因子分析?因子分析(Factor Analysis,简称FA) 是一种统计方法,主要用于降维 和探索变量之间的潜在结构 。它通过识别一组可观测变量背后可能存在的、不可直接观测的潜在变量(latent variables)或因子(factors) ,来解释这些变量之间的相关性。
其基本思路是:试图找出少数几个公共因子 ,这些因子能够解释原始变量之间的相关关系。
因子分析的原理听起来了和主成分分析(PCA)很像不是吗?关于和主成分分析的区别将在本文的最后说明。现在我们来关注一下他的过程。因子分析的一般模型可以表示为:$X=ΛF+ε$ ,其中:
X:p个可观测变量组成的 ...
科研绘图神器推荐:轻松画出专业神经网络结构图
前言科研绘图是所有研究入门的第一课之一,好的绘图会让你的论文更吸引眼球,尽管绘图方面生物信息方向的的绘图很酷炫,快成了美术专业大比拼了。我常常调侃道:作为“研究型人才”,活生生让论文给变成了一个艺术家(😂)。
本文将会缩短你的试错时间,快速让你有目标的去学习和选择科研绘图软件。这将会是科研入门的众多文章中的一个方面,内容很多,本文主要涉及软件推荐。
必要基础首先需要明确一个点,我们最终的目的是科研绘图,也就是说满足科研要求。所以绘图之前需要先了解如下内容:
格式要求科研绘图最终输出的格式可以包括:PNG,JPG,Tif等格式,具体格式要求根据期刊的不同而不同,为了保险起见,请以Tif 格式为唯一输出格式标准。
注:Tif 和 Tiff 指的是同一个格式,之所以你能看见两种文件后缀,是因为早期 MS-DOS(Windows 系统的爷爷)使用的是文件命名规则是:[8.3 filename],所以也就遗传下来了,不过随着近代的发展,已经不限制文件后缀的长度了,所以你会看到两种文件后缀,不过他们本质还是一种文件。
其他标准在了解基础的输出格式后,我们还需要确定一个标准:PPI。当然你 ...
地球化学数据的封闭效应
前言当我们在做机器学习利用地球化学数据分析的时候,例如:分类任务,地球化学异常分析等。涉及地球化学不得不考虑的一个问题是,地球化学的封闭效应所带来的偏差。
封闭效应什么是封闭效应封闭效应 (Closure Effect) ,也称为常数和效应 (Constant Sum Effect) ,是地球化学数据分析中一个需要特别注意的统计现象。 它的产生是由于我们通常使用成分数据 (Compositional Data) 来表示样品的化学组成,例如:
百分比 (%)
百万分率 (ppm)
由于这些数据表示的是各组分占总体的比例 ,它们的总和必然是一个常数 (例如 100% 或 1,000,000 ppm)。这意味着每个元素的含量不是独立的,而是与其他元素的含量相互制约。改变其中一个元素的含量必然会影响其他元素的相对比例。
地球化学数据的封闭效应在数学角度来说,这些数据是存在于一个叫单纯形的空间。
闭合效应可能导致元素之间表现出“伪相关关系”,即表面上看起来元素之间有相关性,但实际上这种相关性是由“定和”约束造成的,而非真正的相互依赖。
由于传统统计方法是基于欧式空间,使得在处理这种成分数 ...

提升成矿预测模型的关键:深度学习数据增强技术指南
前言这部分内容可能和之前有些跨越,我会在后面慢慢补全一些深度学习成矿预测的其他内容。这篇文章的内容涉及在成矿预测,或者成矿远景区预测,成矿远景图预测,或者地球化学异常识别都是一样类似的道理。我们在做成矿预测图(Mineral Prospectivity Mapping, MPM)的时候会不得不面临数据少的问题,对于第一次接触这个的研究人员而言更是头疼。这部分内容将会尽我个人所能去说明这个事情。
本文将围绕如下几点讲述:
什么是数据增强?
**为什么要进行数据增强? **
现在主流的数据增强方法有哪些?
需要注意的是,这部分内容是基于”图像“级别的成矿预测数据,而不是”像素“级别的成矿预测。关于更多的”图像“和”像素“级别的内容可以关注我的个人公众号:码上地球。我会在后续讲述这部分内容。
什么是数据增强数据增强,有的人叫他数据扩增或者数据扩充,他们表达的都是一个意思。指的是一种通过人工生成或变换现有数据来扩大训练数据集规模和质量的技术。
为什么要进行数据增强数据增强终归是因为正/负样本数量不足,导致模型训练效果不佳或者无法训练。更多的问题集中于如下几点:
对于 ...

深度学习入门概要
前言论文进行到了深度学习的相关部分,尤其是当下火热的 CV(计算机视觉)的部分,写到如此我的论文部分也就是开始的地方了,这部分并不会涉及 Pytorch 框架的安装以及基础的 Python 问题,关于这个问题可以参考 【sklearn】机器学习环境搭建,Python 的部分可以参考 Python 。
深度学习框架深度学习框架可以理解为一种工具,就像是现实中的锤子一样,它可以帮助我们更快速方便的捶打一些东西,当然你也可以选择使用别的什么东西来捶打,而这个使用的工具就是不同的深度学习框架,你甚至可以不使用深度学习的框架,完全自己弄的话也是可以的,只不过这个效率上来说会慢很多。
深度学习框架帮助我们封装了很多方法,屏蔽了很多我们不需要关注的细节,例如,求偏导,反向传播等。也许你看到这里并不是很明白这些词是什么意思,并不要紧,慢慢来做下去就会明白了。
全世界最为流行的深度学习框架有PaddlePaddle、Tensorflow、Caffe、Theano、MXNet、Torch和PyTorch。
斜体内容来源:百度百科
在现在来说,主流的只有两大框架:Tensorflow 和 PyTorch ...

蒙特卡洛方法
前言这是一些碎片化知识的集合,我将它们归类为碎片化知识。它们琐碎,且应用层面相对较大,还会涉及到一些其他的知识。
这部分内容将会涉及:概率统计,贝叶斯网络相关内容。
蒙特卡罗法蒙特卡洛方法一般指蒙特卡罗法,蒙特卡罗法也称统计模拟法、统计试验法。是把概率现象作为研究对象的数值模拟方法。是按抽样调查法求取统计值来推定未知特性量的计算方法。蒙特卡罗是摩纳哥的著名赌城,该法为表明其随机抽样的本质而命名。故适用于对离散系统进行计算仿真试验。在计算仿真中,通过构造一个和系统性能相近似的概率模型,并在数字计算机上进行随机试验,可以模拟系统的随机特性。*
内容来源:百度百科
简单来说,蒙特卡洛方法是一种基于随机抽样来解决各种计算问题的算法框架。现在我们来举一个例子来说明它:
使用蒙特卡洛方法计算 π背景圆周率 π 是圆的周长与直径的比率,是一个无理数,大约等于 3.14159。尽管有很多方式可以计算 π,但使用蒙特卡洛方法来估算 π 是一个非常有趣且直观的方式。
步骤
准备一个正方形和一个内切圆:假设有一个边长为 2 的正方形(因此半径为 1 )。在这个正方形内部有一个内切圆。
随机投点:在这个 ...

【sklearn】常见监督分类算法实战
前言终于到了激动人心的地方了,这部分将会说明如何使用sklearn库相关函数来调用并实现相关机器学习模型的训练和预测。对于不懂代码的小伙伴来说,在一般情况下也可以复制并在相关数据集上套用,并对相关参数我会进行说明。
如你所见,这篇标题中指的是:监督学习分类的sklearn机器学习。在参考和使用本篇代码请确保你已经下载安装并配置好 Python 相关环境(如果没有,请参考【sklearn】机器学习环境搭建)和如下举例的包。
关于本篇的说明:
使用的 Python 版本为 3.10.9(理论上你只要是 v3.0 以上就可以)
在相关机器学习的文章中使用但是不限于如下的基本 Python 包,如果有使用其他包,将会在文章内容中做详细说明:
scikit-learn
pandas
NumPy
matplotlib
另外请注意,本篇不会详细说明每个算法的原理,这并不是本文的初衷,所以如果你对算法的原理不了解或者感兴趣可以先了解算法的原理,再参考本文的代码实现
常见集成学习算法
常见分类算法
API
类别
适用类型
K近邻算法(KNN)
sklearn.neighbors
机 ...




