【4.0】C-循环结构及其应用
前言
对于大规模的数据,尤其是相互之间存在一定的联系的数据,怎么表示和组织才能达到高效呢?C语言的数组类型为同类型的数据组织提供了一种有效的形式。
同样的,字符串应用广泛,但C语言中没有专门的字符串类型,字符串是使用字符数组来存放的。
一维数组
一维数组的定义和引用
一维数组的定义
在C语言中使用数组前必须先进行定义。一维数组的定义如下:
1 | //格式声明 |
其中:
类型声明符是任一种基本数据类型或者构造数据类型,即
int,float,char等基本数据类型,以及结构体数据类型。从这里可以看出,数组是建立在其他数据类型的基础之上的,因此数组是构造类型。数组名是用户定义的数组标识符,命名规则遵循标识符命名规则。对于数组元素来说,它们具有一个共同的名字,即数组名。
需要注意的是,数组的名称不可以与其他变量名相同
方括号中的常量表达式表示数组元素的个数,也成为数组的长度。
不能在方括号中用变量来表示数组元素的个数,但可以使用符号常数或者常量表达式
一维数组元素的存储
每个数组元素都占用内存中的一个存储单元,每个元素都是一个变量,可以像以前使用普通变量一样使用,不过使用的是数组的索引。系统在内存中为数组元素分配连续的存储单元。
例如,定义语句int a[15],声明了以下几个问题:
- 数组名为
a - 数组元素的数据类型为
int - 数组元素的下标值是从0开始的。
- 数组名
a是数组存储区的首地址,即存放数组第一个元素的地址。a等价于&a[0],因此数组名是一个地址常量。不能对数组名进行赋值或者运算。
一维数组元素的引用
对数组元素的引用与对变量的引用类似,与变量引用不同的是,只能对单个数组元素进行引用,而不能一次引用整个数组。一维数组元素的引用格式如下:
1 | 数组名[下标] |
【实例】从键盘输入10个整数,求其中的最大数并输出
【代码示例】
1 |
|
【输出】

一维数组的初始化
与一半变量初始化一样,数组的初始化就是在定义数组的同时,给其数组元素赋予初值。
数组的初始化是在编译阶段进行的,这样减少运行时间,提高效率
一维数组的初始化语法格式如下:
1 | //语法格式 |
C语言对数组的初始化有以下几点规定:
可以只给部分数组元素赋初值。例如:
1
int a[10]={0,1,2,3};
只能给数组元素逐个赋值,不能给数组整体赋值。
如果给全部元素赋值,则在数组声明中,可以不给出数组元素的个数。例如:
1
int a[]={1,2,3,4};
一维数组实例
【实例】给定$n$个任意数,按由小到大对其排序,并输出排序结果。
详细看数据结构部分(欠数据结构),经典的排序问题
二维数组
二维数组的定义和引用
前面介绍的数组只有一个下标,称为一维数组,其数组元素也成为单下标变量。在实际问题中,很多问题是二维甚至是多维的,比如常见的矩阵就是二维的,因此C语言允许构造多维数组。
二维数组的定义
二维数组定义的语法格式:
1 | //语法格式 |
其中,常量表达式1表示第一维的长度,常量表达式2表示第二维的长度。
数组元素的个数=常量表达式1 $\times$ 常量表达式2
二维数组的存储
二维数组在概念上是二维的,比如说矩阵,但是其存储器单元是按一维线性排列的。在一维存储器中存放二维数组,有两种方式:一种是按行排列,即放完一行之后顺次放入第二行;另一种是按列排列,即放完一列之后再顺次放入第二列。在C语言中,二维数组是按行排列的。例如:int x[2][3];
先放第一行,即x[0][0],x[0][1],x[0][2],再放第二行,即x[1][0],x[1][1],x[1][2]。如图:

二维数组的引用
与一维数组一样,不能对一个二维数组整体进行引用,只能对具体的数据元素进行引用。语法格式如下:
1 | 数组名[下标1][下标2]; |
要注意下标越界问题,部分编译系统不会检查下标越界问题
二维数组的初始化
二维数组的初始化即定义数组的同时对其元素赋值,初始化有两种方法:
把初始化值括在一对大括号内,例如:
1
int a[2][3]={1,2,3,4,5,6};
初始化的结果是:
x[0][0]=1,x[0][1]=2,x[0][2]=3,x[1][0]=4,x[1][1]=5,x[1][2]=6。把多维数组分解成多个一维数组,也就是把二维数组看作是一种特殊的一维数组,该数组的每一个元素又是一个一维数组。例如:
1
int a[2][3]={{1,2,3},{4,5,6}};
说明:
可以只对部分元素赋值,未赋值的元素自动取0值。
如果对全部元素赋初值,则第一维的长度可以不给出。例如,对二维数组初始化:
1
int x[][3]={1,2,3,4,5,6};
即第一维度的长度可以省略,但是第二维度的长度不能省略。
二维数组的应用实例
【实例】某公司2020年上半年产品销售统计表如下表所示,求每种产品的月平均销售量和所有产品的总月平均销售量。
| 月份 | 产品A | 产品B | 产品C | 产品D | 产品E |
|---|---|---|---|---|---|
| 1 | 30 | 21 | 50 | 35 | 42 |
| 2 | 35 | 15 | 60 | 40 | 40 |
| 3 | 32 | 18 | 56 | 37 | 50 |
| 4 | 40 | 25 | 48 | 42 | 48 |
| 5 | 36 | 23 | 52 | 33 | 46 |
| 6 | 41 | 19 | 55 | 39 | 52 |
【代码示例】
1 |
|
【输出】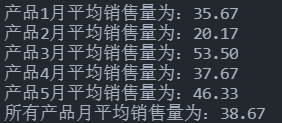
字符数组和字符串
前面说明的都是数值型数组,即数组元素都是数值。还有一种数组,其每个元素都是字符,也就是说数组元素的数据类型是char,初次之外与数值型数组没有区别。
字符串应用广泛,但是C语言中没有专门的字符串类型,字符串是存放在字符数组中的。
字符数组的定义和初始化
字符型数组的语法格式如下:
1 | //语法格式 |
**字符数组也可以是二维或者多维数组,例如:char c[2][2]**。
同样,字符数组也允许在定义时进行初始化赋值,代码示例:
1 | //字符常量赋值 |
**字符型数组初始化时,提供的数据个数如果小于数组元素的个数,则多余的数组元素初始化为空字符\0,而数值型数组初始化为0**。
\0在C语言中定义为NULL,即空字符
【实例】编写程序,输出”Hello,world”。
【代码示例】
1 | //代码一 |
【输出】
如果你足够细心的话,会发现,字符数组的长度多余实际字符长度,详细原因见字符串
【关于字符数组长度=初始化字符长度问题】
如果你使用如下代码输出,就会发现一些奇怪的输出:
1 |
|
如上代码所示,规定5个字符,但是初始化的时候就给5个字符,按照之前说的printf函数必须遇到\0才会停止输出。那么在GCC编译器上,输出的结果为: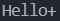
在Visual Studio 2019 IDE上的输出结果为: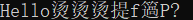
这也是著名的“烫烫烫”问题,详细原因可以参考烫烫烫烫烫烫! - 汇智动力IT学院的文章 - 知乎。
简单来说,对于编译器来说,一次编译过程中会做很多初始化的工作,在这个工作中为了对内存的高效合理化应用,会提前在没用的内存或者需要调度它用的内存写入一些字符来标识,当发生内存溢出的时候,这些本来标识的字符被当作数据处理,例如中文处理,在中文编码就变成了“烫烫烫”。
字符串
前面说明字符串常量时,说明了对于实际字符小于声明字符长度的,其余字符会被\0赋值。因此C编译器以\0来判断字符串是否结束,而不是通过字符长度来判断字符串长度。例如:
1 | char c[6]={"China"}; |
赋值结果为:数组c含有6个字符,前五个组成”China”,最后一位字符为\0,即空字符。
需要注意的是:
初始化字符数组时不可以超出数组长度
用字符串常量初始化时,字符数组长度可以省略,其数组存放字符个数由赋值的字符串长度决定。
实际长度=实际字符长度+1(
\0)用字符常量初始化时,如果省略字符数组长度,则实际长度=实际字符长度。
字符数组的输入和输出
字符数组的输入和输出有两种方法:一种是逐个把字符输入/输出,另一种方法是整个字符串一次输入/输出。
**scanf/printf函数可以输入/输出任何类型的数据,若要输入/输出字符,则格式为%c,若要输入/输出字符串,格式为%s**。
字符数组的输入。从键盘逐个读取字符:
1
scanf("%c",字符数组元素地址);
从键盘读取一串字符:
1
scanf("%s",字符数组名);
字符数组的输出。从键盘逐个输出字符:
1
printf("%c",字符数组元素地址);
从键盘输出一串字符:
1
printf("%s",字符数组名);
需要注意的是,输出字符串时,遇到
\0则结束。
【关于输入字符串超出数组字符长度问题】
问题源于如下代码,代码很简单,输入字符串,输出字符串:
1 |
|
如果我们正常按照字符数量输入字符,则输出结果: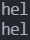
但是如果我们故意多输入一些字符,则输出结果: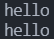
首先我们需要明确几点规则:
- 对于字符数组,每个字符数组最后一位一定是一个
\0字符。 - 对于
printf()函数来说,输出字符是自动截取到\0字符。 - 对于数组溢出问题,不在C编译器的预编译报错范围,也就是说数组溢出问题需要程序员自行负责。
所以对于直接获取字符串输入来说,获取多少编译器就在最后+\0字符,然后printf函数输出字符串,是读取到\0才会停止,导致即使超出字符数组长度,也可以原样输出的原因。
那么问题升级一下,如果我在输入字符串的时候,输入了空格会怎么办?代码示例:
1 |
|
【输出】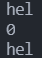
0对应的是ASCII码的
NULL,即空字符,也就是C语言的\0。
可以看到,如果我们在输入字符串的时候,输入空格,那么空格会被默认为\0字符,即NULL(空字符)。那么,我们真的想要输出空格怎么办?
可以使用%[^\n]来告诉输入函数,以回车作为字符串输入的结束。对于上面的代码,我们修改后:
1 |
|
【输出】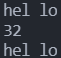
可以得知,32是ASCII的空格字符。在输入的时候,我们规定编译器在回车的地方认为是字符串的结束,即在该处加上了\0字符,这样就解决了这个问题。
字符串处理函数
**在C语言标准库函数中,提供了一些专门用于处理字符串的函数,常用的有gets(),puts(),strlen(),strcmp(),strlwr,strupr(),strcat(),strcpy(),strncpyy()**函数。
在使用这些函数之前,需要引入专门的函数库,即
#include <string.h>
gets(),puts()是字符串输入/输出函数。其中,
gets()函数是字符串输入函数。语法格式如下:1
gets(字符数组名);
函数功能:获取输入的字符串到指定变量中。
1
puts(字符数组名);
函数功能:输出指定字符串,同
printf,也是截取到字符\0。strlen()函数事获取字符串长度函数。语法格式如下:strlen是英文string length的缩写,即字符串长度。1
strlen(字符数组名);
在Visual Studio 2019 编译器上是截取
\0之前的字符实际长度,而在GCC编译器中,是截取全部的字符长度,即包含\0字符的长度。(修正:如果字符数组长度没有大于实际长度1位,这输出的长度包含\0字符,即实际长度+1,反之,这输出正确的数组实际长度)strcmp()函数是字符串比较函数。语法格式如下:strcmp是英文string compare的缩写,即字符串比较。1
strcmp(字符数组1,字符数组2);
函数功能:将两个字符数组的字符串从左到右逐个比较,比较字符的ASCII码大小,并由函数返回值返回比较结果。(字符串的比较原理:每个字符串ASCII码的和做比较)
- 字符串1=字符串2,返回值=0
- 字符串1>字符串2,返回值>0
- 字符串1<字符串2,返回值<0
【大坑说明】
注意这里有个大坑,如果我们常规的字符数组初始化
char c[2]={"he"};末尾没有\0字符,则编译器在获取该字符串的时候会溢出,也就是说编译器底层获取的c[2]实际的值已经不是he了。而对于scanf()/puts()来说,它会自动在最后加上\0字符,所以不会出现这种问题。当初始化字符数组规定字符=实际赋值,这会出现
\0字符丢失,如果按照C语言规定,初始化数组时规定字符> 实际初始化赋值一位,则不会出现这个问题strlwr()和strupr()函数,是字符串大小写转换函数。函数语法格式如下:strlwr是英文string lower(case)的缩写,即字符串小写(字母)struper是英文string upper(case)的缩写,即字符串大写(字母)1
2
3
4//转换小写字母函数
strlwr(字符数组名);
//转换大写字母函数
strupr(字符数组名);代码示例:
1
2
3
4
5
6
7
8
int main(){
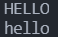
char c[6] = {"hello"}; //小写字母初始化
char b[6] = {"HELLO"}; //大写字母初始化
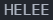
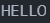
puts(strupr(c)); //转换为大写
puts(strlwr(b)); //转换为小写
}输出结果:

strcat()是字符串连接函数。语法格式如下:strcat是英文string catenate的缩写,即字符串连接。1
strcat(字符数组名1,字符数组名2);
函数功能:把字符数组2中的字符串连接到字符数组1中字符串的后面,并删去字符串1后的串标志
\0。函数返回值为字符数组1的首地址。代码示例:1
2
3
4
5
6
7
int main(){
char c[16] = {"hello"};
char b[6] = {"HELLO"};
puts(strcat(c, b)); //拼接字符串数组
}输出结果:
需要注意的是,合并字符数组时,第一个字符数组的长度要足够长,否则不足以容纳全部字符数组2
strcpy()/strncpy()是字符串复制函数。语法格式如下:strcpy是英文string copy的缩写,即字符串复制。1
2
3
4//复制全部字符数组
strcpy(字符数组1,字符数组2);
//复制指定长度的字符串数组
strncpy(字符数组1,字符数组2,n);函数功能:(
strcpy)把字符数组2中的字符串复制到字符组1中。串结束标志\0也一同复制;(strncpy)把字符数组2中的前n个字符复制到字符数组1中,取代字符数组1中原有的前n个字符。代码示例:1
2
3
4
5
6
7
8//strcpy
int main(){
char c[6] = {"hello"};
char b[6] = {"HELLO"};
puts(strcpy(c, b));
}输出结果:
1
2
3
4
5
6
7
8
9
10//strncpy
int main(){
char c[16] = {"helloleoleiming"};
char b[6] = {"HELLO"};
strncpy(c,b,6); //复制字符数组b前六个字符到C
c[6] = '\0'; //将c的第七个字符变为结束字符“\0”
puts(c);
}输出结果:
如果你足够细心,会疑问直接复制不可以吗?为什么要多此一举?**实际上
strncpy函数不会给末尾加上结束符号,即\0**。所以需要手动添加。我在GCC编译器上测试这样是可以通过的,但是在Visual Studio 2019上测试不通过,原因还是上面提到的实际上
strncpy函数不会给末尾加上结束符号,即`\0。- 个人感觉这是个历史遗留问题,此方法暂时不建议使用。

字符数组应用实例
【实例】编程实现凯撒加密,即是将加密文本中的每个字符替换成为其后面的第k个字符。
【代码示例】【伪装凯撒加密】
1 |
|
输出结果:




